AutoEncoders in Keras: GAN
With all the advantages of VAE variational autoencoders, which we dealt with in previous posts, they have one major drawback: due to the poor way of comparing original and restored objects, the objects they generated are similar to the objects from the training set, but they are easily distinguishable from them (for example blurred).
This disadvantage is much less pronounced in another approach, namely, generative competing networks - GANs.
(The real reason why VAEs produce blurred images is because of the way we define likelihood when comparing original and restored object. Namely, we suppose that pixel values are independent from each other (likelihood factorizes into product of likelihoods for each pixel). GANs don’t make this assumption (because we don’t define the likelihood at all), and thus are not restricted by it.)
Formally, GANs, of course, do not belong to autoencoders, however there are similarities between them and variational autoencoders, they will also be useful for the next part. So it will not be superfluous to meet them too.
GAN in brief
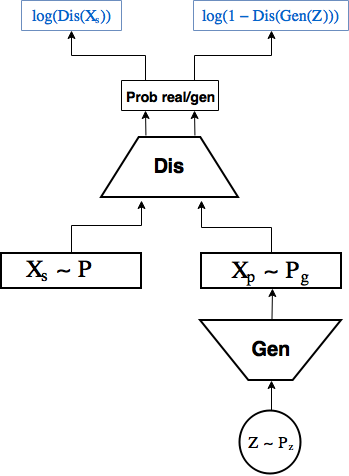
GANs were first proposed in article [1, Generative Adversarial Nets, Goodfellow et al, 2014] and are now being actively studied. Most state-of-the-art generative models one way or another use adversarial.
GAN scheme:
Full Russian text is available here